
|
|
|
|
Students investigate the behavior of disk scheduling algorithms
by using a simulation program.
The following information can be found below:
Title: An Investigation of Disk Scheduling Algorithms
Summary:
1) Students study a program that simulates disk scheduling algorithms
and answer a set of questions about it. This part of the laboratory
project could be skipped.
2) The students use the program to generate data that reflects
the performance of the First Come First Serve and the Shortest
Seek Time First algorithms under a variety of conditions (request
arrival rates of 10, 20, 30, and 40 per second, distributed exponentially;
4 or 50 sectors per track). For each algorithm under each situation
the program simulates how the algorithm would handle the situation
and calculates the expected service time between requests, the
expected waiting time for a request, and the standard deviation
of these waiting times. The students graph the 48 data points
and then use their graphs and their knowledge of disk scheduling
algorithms to answer another set of questions. This is the heart
of the laboratory project.
Additional Exercise A: The students could implement the simulation
of the Look Algorithm, collect the data about it from the simulation,
and answer a question about the differences between Look and SSTF.
The current simulation program is designed so that it is easy
to add the Look simulation; the students just have to code the
Look algorithm.
Additional Exercise B: An optional wrap up exercise is to have
the students read the article that this lab is based on, A
Comparative Analysis of Disk Scheduling Policies by Teorey
and Pinkerton, CACM, 3/72, and answer some questions about the
article.
Content Area: Operating Systems
Level: Intermediate
Topics: Disk scheduling algorithms
Type of Interaction: Designed for individual work; however,
since the construction of the graphs is tedious, it might be possible
to distribute this work among students and allow them to share
the completed graphs. Optimally, students should use some type
of graphing software to automatically generate graphs from an
output data file generated by the program.
Pre-requisites: Before students try this lab they should
already understand something about disk scheduling. A "standard"
lecture on disk scheduling algorithms should suffice: describe
the problem and define the classic algorithms (FCFS, SSTF, SCAN,
LOOK). See Silberschatz and Galvin's Operating Systems Concepts,
4th edition, Addison Wesley, Section 12.2 for a review of disk
scheduling algorithms.
If the students are not familiar with random number generation
techniques or with the use of simulation to analyze processes,
then a short lecture on these topics should be given. The program
used in this laboratory project generates random numbers for uniform
and exponential distributions.
Goals/Objectives: Teach about disk scheduling algorithms;
demonstrate the usefulness of simulation, especially as a tool
for investigating systems; exposure to operating systems research
(even though it is from 1972); exposure to a non-trivial program.
Learn the FCFS, SSTF, and LOOK disk scheduling algorithms; use
simulation; use graphing tools.
Time:
Before the lab session:
Validation: This laboratory project has been used successfully
several times by the author in an open lab format.
Feedback location:
Resources and materials required:
1. Pascal compiler and run time environment.
2. Graphing software strongly suggested.
Also, the following files are required for this lab:
Hints: Be careful of machine imposed restrictions on the
random number generation code contained in the disksim program
that is used in this lab. Random Number Generators: Good Ones
are Hard to Find by Stephen K. Park and Keith W. Miller, CACM,
October 1988, Volume 31, Number 8, page 1192, is a clearly written
discussion of the requirements for a random number generator and
includes several algorithms for generating random numbers, one
of which should work on your system. The disksim.pas program uses
the "Integer Version 2" version of their minimal standard
random number generator, which should work for systems for which
maxint is 2^31-1 or higher. If you want to use the program in
a Turbo Pascal system you should change the appropriate integer
variables to longints.
You might consider devoting an entire laboratory session to the
investigation of random number generation before attempting this
laboratory project. Students could test various random number
generators and determine which version of Park and Miller's minimally
perfect RNG works on their system. You could also study how to
take random numbers that are based on a uniform distribution and
transform them into random numbers based on other distributions.
When covering disk scheduling, in addition to considering the
goal of minimization of average seek time you should also cover
the idea of minimizing average wait time, plus the concept of
seek or wait time standard deviation and why we might want to
minimize them (to provide reliable service time). Rotational delay,
also known as latency, is also figured into the simulation, as
is transfer time, so they should be covered.
Title: An Investigation of Disk Scheduling Algorithms
Course: Operating Systems, Computer Performance Modeling
Topic: Disk Scheduling
Resources and materials required: Pascal compiler and run
time environment. Graphing software strongly suggested.
The following text files are also required or are useful for this
lab:
Goals: In addition to learning about disk scheduling algorithms
you will see the usefulness of simulation, especially as a tool
for investigating systems and be exposed to operating systems
research (even though it is from 1972) and to a non-trivial program.
Name:
Notes: Do NOT work together. Use these sheets for your final answers (do rough work somewhere else.)
Prelude: The underlying purpose of this assignment is not to teach about disk scheduling, although you will certainly learn something about that topic. The purpose is threefold. First, to introduce you to the usefulness of simulation, especially as a tool for investigating systems. Second, to expose you to some accessible yet challenging operating systems research, albeit research that is many years old. Third, to expose you to a non-trivial program.
First Movement: "Libretto'', i.e. "Read'',
i.e. you do not need to run any program to obtain the answers
in this section. You only need to read and study the disksim program.
Of course, if you like, you may also run the programs, perhaps
to verify your answers.
Circle one: EARLIER LATER
Line(s):
Second Movement: "Chorus''
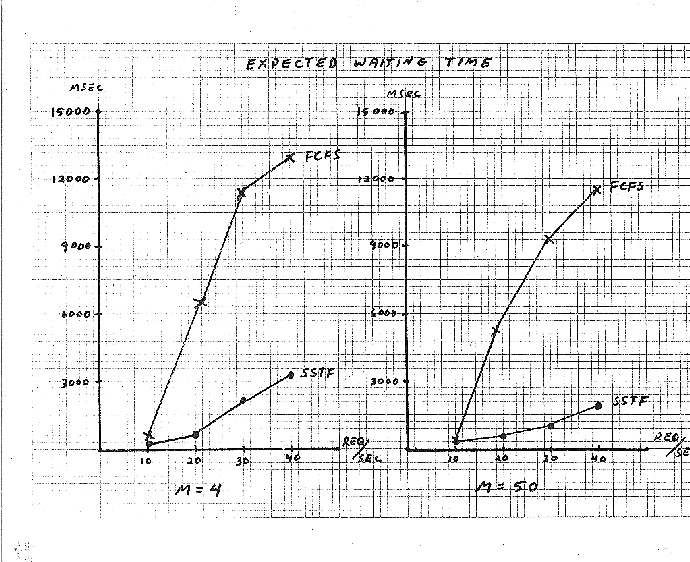
Run DISKSIM. Use 27349 as the random number seed. Graph the
output as shown in the graph sample. You
should have a pair of graphs for each of the three performance
measures. Use the same scale for M = 4 and M = 50. Staple your
graphs to the back of these sheets. Use the program output and
your graphs to answer the questions in this section.
Third Movement: "Variations on a Theme''
Additional Exercise A: "Improvisation" - Add the
code for the Look disk scheduling algorithm to the simulation
program. Add a new line of information to each of your graphs
that represents the data collected from the simulation of the
Look algorithm.
Write an essay that addresses the question "Which algorithm
is better, SSTF or Look?"
Additional Exercise B: "Studying the Classics" -
Read "A Comparative Analysis of Disk Scheduling Policies''
by Teorey and Pinkerton, Communications of the ACM, March 1972.
Do not worry about understanding everything in the article. Just
understand enough to get an idea of their research, what it was
about and what it entailed, and to answer the following questions.
{kind=link}